A major outage at Cloudflare one of the world’s most widely used internet infrastructure providers triggered widespread service disruptions on November 18, 2025, sending ripple effects across the global web and briefly rendering countless platforms partially or completely inaccessible.
Internal Failure Triggers Global Impact
The disruption originated from an internal service degradation within Cloudflare’s network that began producing HTTP 500 errors across several of its core systems. The failures affected the company’s dashboard, API, and underlying network services, leaving millions of users struggling to access websites relying on Cloudflare for security, DNS, and content delivery.
Cloudflare acknowledged the incident at 11:48 UTC, reporting intermittent impact and promising immediate remediation. By 12:03 UTC, the investigation remained underway; at 12:21 UTC the company noted signs of recovery but warned customers to expect elevated error rates. Another update at 12:37 UTC confirmed continuing work with no full resolution in sight throughout the afternoon.
Ironically, Cloudflare’s own status page went down during the height of the outage, preventing users from checking updates in real time.
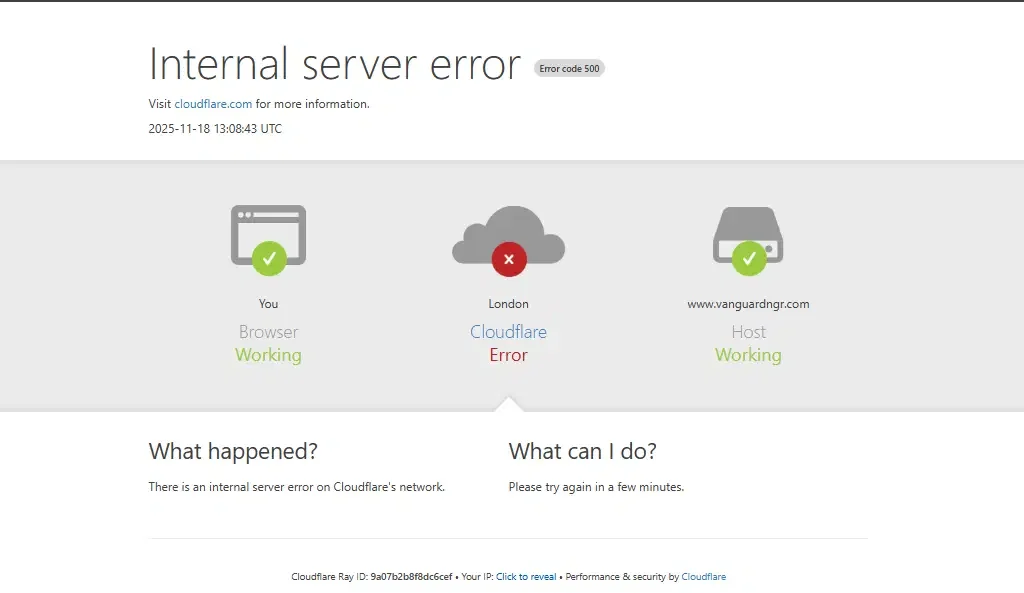
The failure cascaded through major online platforms, many of which depend on Cloudflare’s CDN, DDoS protection, and DNS services.
- X (formerly Twitter) was hit particularly hard, with widespread loading issues and error messages citing Cloudflare server failures. Downdetector logged more than 11,000 user reports at peak, the majority tied to the mobile app.
- AI platforms such as OpenAI’s ChatGPT and Perplexity AI were unreachable for many users, displaying Cloudflare-branded error pages urging retry attempts.
- Other affected services included Canva, Spotify, Discord, League of Legends, Shopify, Medium, multiple crypto exchanges, and even Letterboxd.
- Outage tracker Downdetector itself briefly experienced issues, compounding user frustration as reports surged worldwide.
The crisis recalled the recent Amazon Web Services incident in October, which underscored the growing vulnerability of global systems reliant on a small number of cloud infrastructure providers.
Maintenance and Third-Party Issues Add Complexity
Concurrent maintenance activities in several Cloudflare datacenters—including Los Angeles, Atlanta, Santiago, and Tahiti may have contributed to latency and added strain as traffic was rerouted through alternative regions. Meanwhile, a separate problem affecting Cloudflare’s third-party support portal limited customers’ ability to view cases, though responses remained functional.

Ongoing Recovery and Industry Context
As of 6:24 PM IST, Cloudflare reported gradual recovery across its network, though elevated error rates persisted in regions of Europe, North America, and Asia. The company emphasized its ongoing mitigation efforts and promised a detailed post-incident analysis once the situation was fully resolved.
The outage comes amid a tense period for global cloud infrastructure. On October 20, AWS suffered a 15-hour disruption in its US-EAST-1 region, impacting platforms such as Slack, Snapchat, and Atlassian. Nine days later, an accidental DNS configuration change at Microsoft Azure triggered a worldwide outage affecting Azure Front Door and CDN services.
Cloudflare’s latest update at 14:34 UTC confirmed that dashboard functionality had been restored, though broader application services were still in remediation.
Add a Comment