Princeton University disclosed a cybersecurity incident involving unauthorized access to one of its University Advancement databases, after external attackers infiltrated the system on November 10, 2025. The intrusion, which lasted less than 24 hours, exposed personal information belonging to a broad segment of the university community.
According to university officials, the affected database included names, email addresses, phone numbers, residential and business addresses, and details related to fundraising interactions and donation histories. The information pertained to alumni, donors, faculty members, students, parents, and other connected individuals.
Crucially, the compromised system did not generally contain Social Security numbers, passwords, credit card details, bank information, or protected student records governed by federal privacy laws.
Still, the exposure of contact information and donor-related details has prompted concerns about targeted phishing attempts seeking to exploit the breach.
Rapid Detection and Incident Response
Princeton’s cybersecurity team identified the suspicious activity within 24 hours of the initial breach, swiftly removing the unauthorized actors from the system. The university immediately engaged external cybersecurity specialists and notified law enforcement to assist with the forensic investigation.
By November 15, Princeton began issuing alerts to individuals who may have been affected, urging them to remain cautious of unsolicited messages especially those asking for sensitive data.
University representatives emphasized that legitimate staff will never request Social Security numbers, banking details, or account passwords via email, phone calls, or text messages.
Investigators confirmed that no other university systems were compromised during the attack. While some campus services experienced disruptions beginning November 14, officials have not stated whether those issues were related to the breach.
To support community members seeking more information, Princeton launched a dedicated resource page and established a specialized email address for inquiries.
Ongoing Investigation Into Scope of Access
The university’s response team continues to work alongside cybersecurity experts to analyze the attack vectors and determine precisely what data was viewed or extracted. Officials have not yet disclosed the full extent of the attackers’ access but stressed that containment measures were implemented quickly to prevent further intrusion.
Princeton will continue providing updates to affected individuals as new findings emerge from the ongoing forensic review.
Since its emergence in 2023, DragonForce has rapidly evolved from a ransomware-as-a-service (RaaS) operation into a sophisticated cybercriminal cartel. Initially relying on the LockBit 3.0 builder for developing its encryptors, DragonForce made a significant leap when it adopted the Conti v3 source code, which had been leaked publicly. This move not only enhanced its technical capabilities but also positioned DragonForce as a formidable player in the growing ransomware ecosystem.
By early 2025, DragonForce rebranded itself as a cartel, marking a pivotal shift in its operations and business model. Instead of functioning as a traditional ransomware group, the cartel structure now allows affiliates to white-label its payloads, create their own branded ransomware variants, and operate with greater independence while still using DragonForce’s robust infrastructure and support system.
The Cartel Model – A New Approach to Ransomware
One of the most striking elements of DragonForce’s evolution is its cartel-like structure. By offering affiliates an 80% profit share, the group removes many of the technical barriers to entry that typically hinder smaller operators. This model not only incentivizes the recruitment of new affiliates but also lowers the entry threshold for would-be cybercriminals, expanding the group’s reach and operational footprint.
DragonForce’s cartel infrastructure provides affiliates with everything they need to launch successful ransomware attacks. This includes:
Automated deployment systems to streamline attacks
Customizable encryptors that can be tailored to specific targets
Reliable, 24/7 monitored infrastructure to support operations
Support for multiple platforms, including Windows, ESXi, Linux, BSD, and NAS systems
This wide-reaching technical infrastructure makes DragonForce’s operations highly scalable and adaptable to different targets across various sectors.
Partnering with Scattered Spider: A Dangerous Duo
DragonForce’s rise is also closely tied to its partnership with Scattered Spider, a financially motivated initial access broker known for its expertise in social engineering and multi-factor authentication (MFA) bypass techniques. Scattered Spider specializes in conducting reconnaissance on employees through social media and open-source intelligence, using this information to craft convincing phishing campaigns and voice phishing attacks.
Once credentials are compromised, Scattered Spider deploys remote monitoring tools like ScreenConnect and AnyDesk to establish persistence on the target network. From there, DragonForce conducts extensive network reconnaissance, with a particular focus on backup infrastructure, credential repositories, and VMware environments, all key targets for maximizing the impact of their ransomware attacks.
Technical Advancements: Stronger, Smarter Malware
What truly sets DragonForce apart from other ransomware operations is its technical sophistication. The group has demonstrated an ability to quickly adapt and improve its tactics in response to emerging threats and vulnerabilities. Notably, after researchers disclosed weaknesses in the Akira ransomware’s encryption methods, DragonForce swiftly improved its own encryption mechanisms to stay ahead of the curve.
DragonForce uses ChaCha20 encryption for its configuration files and generates unique encryption keys for each targeted file, making it harder for defenders to detect or reverse the encryption process. In addition, DragonForce employs multiple encryption modes—full, header, and partial encryption—with configurable thresholds that allow for customizable encryption strategies based on the type of file being targeted.
The Growing Threat of BYOVD Attacks
Another alarming technical advancement employed by DragonForce is the use of BYOVD (Bring Your Own Vulnerable Driver) attacks. This method involves exploiting vulnerable drivers such as truesight.sys and rentdrv2.sys to terminate security software and protected processes. By communicating with these drivers through DeviceIoControl functions using specific control codes, DragonForce is able to bypass endpoint detection and response solutions and maintain a foothold in the target system.
The malware is designed to target specific processes during encryption, including SQL Server instances, Oracle databases, and Microsoft productivity applications. This targeted approach helps maximize the success rate of encryption and ensures that critical systems are impacted.
Widespread Impact: DragonForce’s Growing Reach
Since its inception, DragonForce has impacted over 200 victims across various industries, including retail, airlines, insurance, managed service providers, and large enterprise sectors. One of the most notable attacks attributed to DragonForce and its partner, Scattered Spider, was the Marks & Spencer breach, which showcased the group’s operational effectiveness.
As DragonForce continues to recruit new affiliates, acquire rival infrastructure, and expand its cartel model, it is poised to become an even more dominant force in the world of ransomware.
A Concerning Evolution in Cybercrime
DragonForce’s transformation from a simple ransomware-as-a-service operation to a full-fledged cybercriminal cartel represents a troubling shift in the landscape of cybercrime. The cartel structure not only makes it easier for cybercriminals to enter the ransomware business but also ensures that DragonForce maintains control over its vast network of affiliates and operations.
As the group continues to recruit new talent and refine its tools and tactics, its ability to target high-value entities will only increase. For businesses and organizations, this represents a growing and evolving threat that requires heightened vigilance, stronger cybersecurity defenses, and proactive measures to mitigate the risks posed by these sophisticated ransomware operations.
October 24, 2025, Cybersecurity researchers warn that email phishing attacks have reached a critical inflection point this year, as threat actors deploy increasingly sophisticated evasion techniques designed to bypass traditional security tools and deceive even well-trained users.
According to new research from Secure list and other security firms, the phishing landscape in 2025 has evolved dramatically. Attackers are combining revived older methods with new delivery mechanisms that exploit weaknesses in automated scanning systems and human behavior
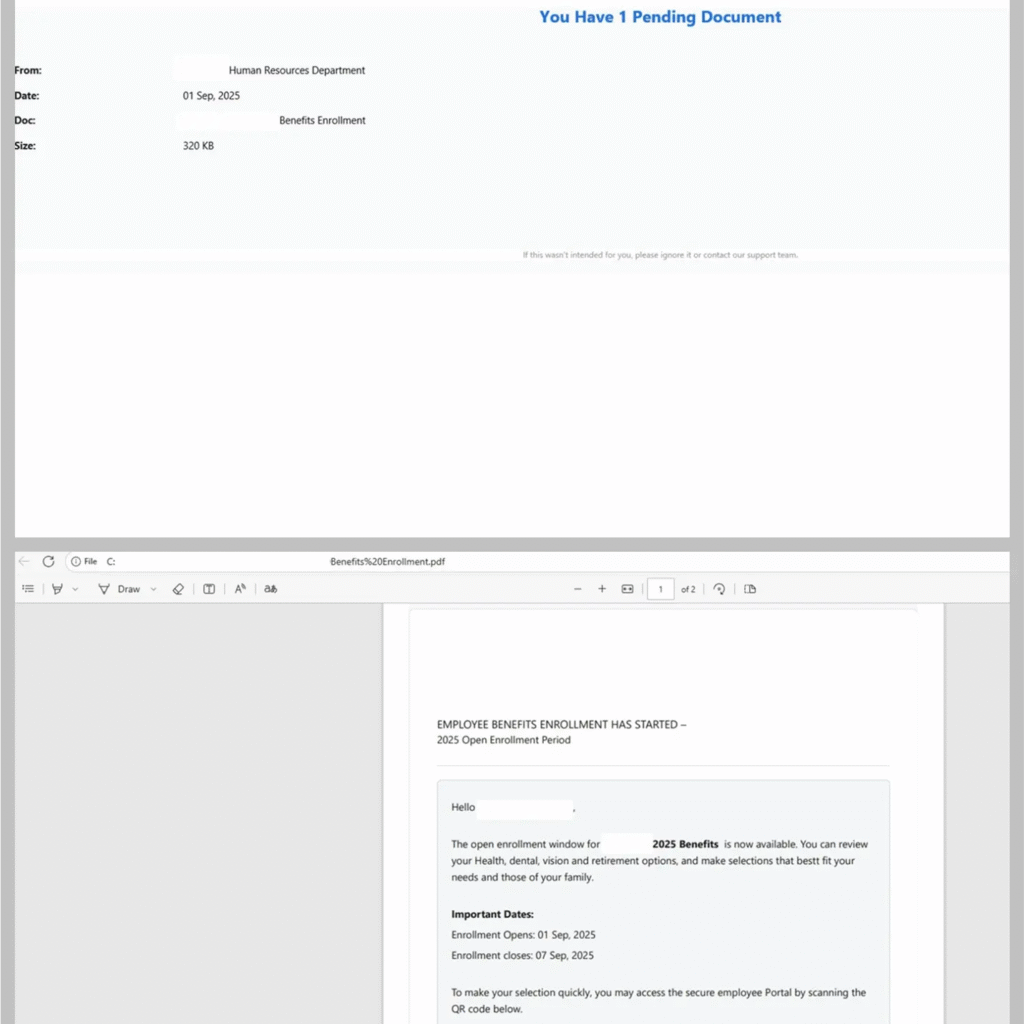
PDF Attachments Replace Links as Primary Attack Vector
Researchers have documented a sharp rise in phishing campaigns that use PDF attachments instead of traditional hyperlink-based lures. These PDFs often contain QR codes that, when scanned, lead users to malicious websites designed to harvest login credentials.
This shift allows cyber criminals to bypass email filters that scan for malicious links while encouraging victims to use mobile devices, which typically lack enterprise-grade security protections.
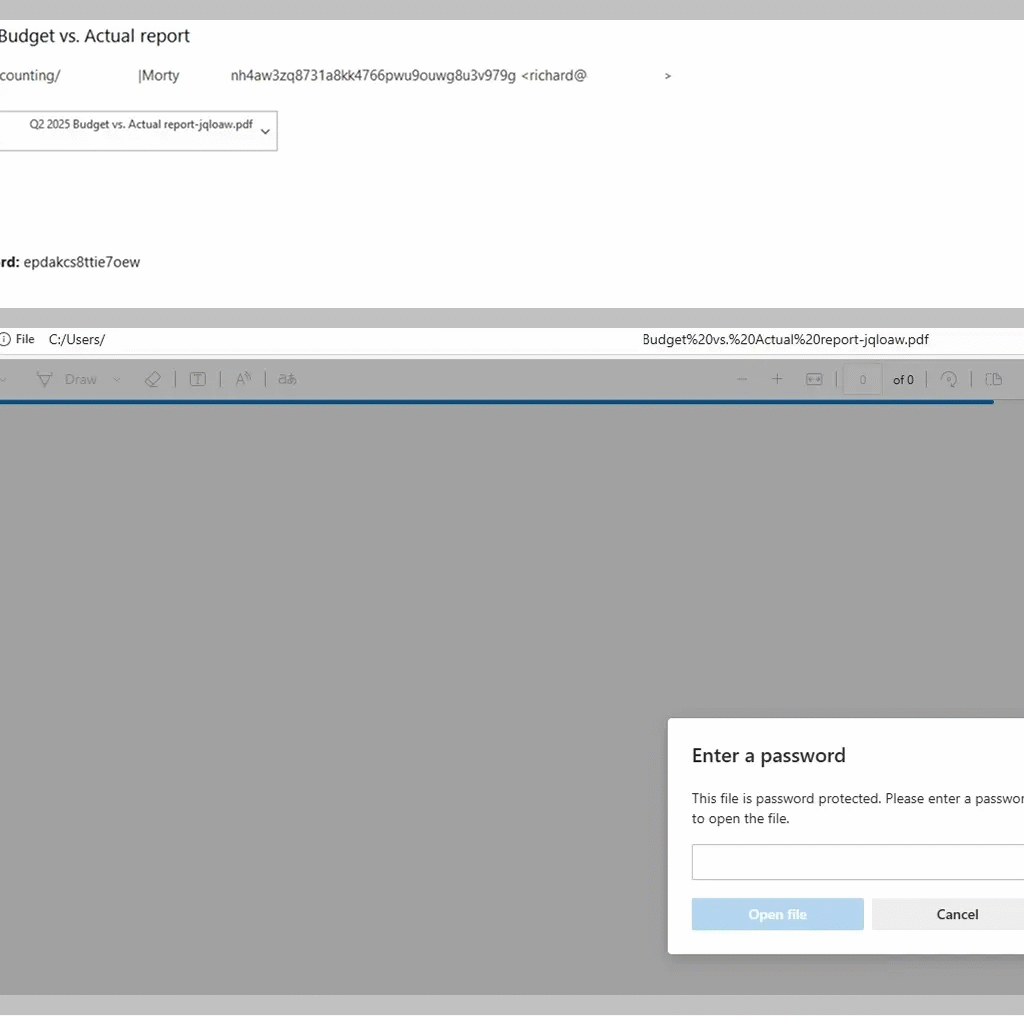
Secure list analysts report that these PDF-based phishing attacks have become more advanced, often using encryption and password protection to evade automated file scanning. In many cases, attackers send passwords in a follow-up message, a tactic that complicates detection and adds a false sense of legitimacy.
Security experts say this approach leverages psychological manipulation, mimicking corporate security protocols to increase user trust and compliance.
Calendar-Based Phishing Makes a Comeback
In a trend not seen since 2019, calendar-based phishing has re-emerged as a popular attack method. Instead of embedding phishing links in email bodies, cyber criminals insert them into calendar event descriptions.
Because calendar platforms automatically send reminders that often bypass email security checks, this strategy has proven especially effective in business-to-business (B2B) environments and corporate offices.
New Techniques Target MFA and Cloud Services
Phishing infrastructure in 2025 is more advanced than ever, with attackers implementing multi-layered evasion techniques that mimic legitimate authentication processes.
One increasingly common tactic involves CAPTCHA verification chains, requiring users to confirm they are human before proceeding to credential-harvesting pages. These CAPTCHAs frustrate automated scanners while preserving access for real users.
Researchers have also observed a surge in phishing campaigns targeting cloud storage and authentication services. In these cases, malicious websites interact directly with legitimate APIs in real time, mirroring the behavior of genuine login systems.
When victims enter their credentials, the phishing site communicates with the real platform, displaying authentic error messages and MFA prompts. This technique enables attackers to steal both passwords and one-time authentication codes, effectively bypassing multi-factor authentication (MFA).
Pixel-Perfect Phishing Pages Increase Realism
The visual fidelity of phishing pages has also improved. Attackers are now building pixel-perfect replicas of legitimate login portals, complete with corporate logos, folder structures, and interface details. These replicas make it nearly impossible for users to distinguish fake pages from real ones.
Once credentials are harvested, attackers can access accounts undetected, posing serious risks to businesses and individuals alike.
Experts Urge Layered Defense Strategies
Cybersecurity specialists warn that traditional email filters are no longer sufficient to counter these emerging threats. Experts recommend a multi-layered defense approach, including:
Continuous security awareness training for employees
Deployment of AI-driven email filtering tools capable of analyzing attachments and behavior patterns
Enhanced monitoring of authentication activity to detect suspicious access attempts
“The phishing attacks we’re seeing in 2025 are far more adaptive and convincing than anything we’ve encountered before,” said a Secure list analyst. “They blur the line between legitimate and malicious activity and that makes user education and detection technology more critical than ever.”
Oracle has disclosed multiple critical vulnerabilities in its Oracle VM VirtualBox virtualization software, potentially allowing attackers to achieve complete control over the VirtualBox environment.
These flaws, detailed in the October 2025 Critical Patch Update (CPU), affect the Core component of VirtualBox versions 7.1.12 and 7.2.2, enabling high-privileged local attackers to compromise confidentiality, integrity, and availability with devastating consequences.
The disclosure highlights the ongoing risks in virtualization platforms, where even local access can lead to broader system impacts due to scope changes.
Experts warn that these vulnerabilities could facilitate full takeover scenarios, making immediate patching essential for users relying on VirtualBox for development, testing, and secure isolation.
No evidence of active exploitation has surfaced yet, but the high CVSS scores underscore the urgency.
Oracle’s advisory emphasizes that while exploitation requires high privileges and local access, the potential for unauthorized data access and denial-of-service attacks remains a severe threat.
Vulnerability Breakdown And Affected Versions
The October 2025 CPU addresses nine specific CVEs in VirtualBox’s Core, all classified as local exploits without remote authentication.
These issues stem from improper privilege handling and unsafe actions, allowing attackers with infrastructure logon to escalate control.
The most severe, including CVE-2025-62587 through CVE-2025-62590 and CVE-2025-62641, carry a CVSS 3.1 Base Score of 8.2, indicating high risk due to low attack complexity and changed scope.
For a comprehensive overview, the following table summarizes the CVEs, affected products, scores, and impacts based on Oracle’s risk matrix:
Lower-severity flaws like CVE-2025-61759 and CVE-2025-62591 to 62592 score 6.0 to 6.5, focusing on confidentiality breaches without integrity or availability disruption.
All vulnerabilities require local access but can propagate beyond VirtualBox due to scope changes. Successful exploitation could result in the complete takeover of the VirtualBox environment, exposing sensitive virtual machine data and enabling malware persistence across isolated systems.
For enterprises using VirtualBox in development pipelines or as a lightweight hypervisor, this poses risks of data leaks, ransomware deployment, or lateral movement in networks.
Individual developers might face personal data compromise if running untrusted guest OSes. The high integrity and availability impacts (scoring High) could cause crashes or unauthorized modifications, disrupting workflows.
While no public proofs-of-concept exist, the flaws’ similarity to past virtualization bugs raises concerns about targeted attacks.
Mitigations
Oracle urges users to apply the October 2025 CPU patches immediately, available via the official download portal.
Beyond patching, organizations should enforce least-privilege access, monitor high-privileged accounts, and audit VirtualBox configurations for unnecessary exposures.
Disabling unused features and isolating VirtualBox instances in segmented networks can mitigate risks. For those unable to patch promptly, temporary workarounds include restricting logon privileges and validating system integrity regularly.
Atlassian has issued an urgent security advisory for a high-severity path traversal vulnerability in Jira Software Data Center and Server, tracked as CVE-2025-22167. The flaw allows authenticated attackers to write arbitrary files anywhere accessible to the Java Virtual Machine process, a capability that could lead to data corruption, service disruption, or even code execution.
With a CVSS score of 8.7, this vulnerability affects Jira versions 9.12.0 through 11.0.1. Atlassian discovered the issue internally and has released patches addressing it in 9.12.28, 10.3.12, and 11.1.0.
What’s Behind the Vulnerability
The problem lies in insufficient input validation within Jira’s file handling mechanisms. Attackers with low-level authenticated access can exploit it by crafting malicious requests that include traversal sequences such as ../. This technique lets them bypass directory restrictions and write data to unintended locations on the server.
Because the attack is network-based, requires no user interaction, and involves low complexity, it can be exploited remotely by anyone with valid Jira credentials.
While the flaw primarily enables arbitrary file writes, Atlassian warns it could potentially be chained with other vulnerabilities to achieve data exfiltration or remote code execution.
Impact on Organizations
For teams relying on Jira for project management and DevOps, the risks are serious. Exploitation could lead to:
Corrupted configuration or project data
Malware deployment
Database tampering
Log deletion or alteration
Denial-of-service (DoS) scenarios
In regulated industries such as finance, healthcare, or government, even indirect exposure could result in compliance violations or intellectual property loss.
Although no public exploits have been reported, the low barrier to attack requiring only basic authentication that makes prompt patching essential, especially for internet-exposed instances.
How to Protect Your Jira Environment
Atlassian strongly advises all customers to upgrade immediately to one of the patched versions:
9.x branch: 9.12.28 or later
10.x branch: 10.3.12 or later
11.x branch: 11.1.0 or later
If an immediate upgrade isn’t possible, Atlassian recommends the following interim mitigations:
Restrict filesystem write permissions for the JVM process
Limit network access to Jira instances
Deploy file integrity monitoring to detect suspicious changes
Maintain regular backups and security audits
Why This Matters
This incident highlights both the complexity of modern software supply chains and the importance of rapid patch management. Atlassian’s swift internal discovery and disclosure demonstrate proactive security practices — but delayed updates could still leave thousands of systems exposed.
With over 200,000 organizations worldwide depending on Jira for critical workflows, timely action is the best defense against potential exploitation.
A widespread AWS outage on Monday caused major disruptions across the internet, affecting millions of users and temporarily disabling a long list of popular platforms and services — from e-commerce and social media to financial apps and design tools.
The outage began early Monday morning and quickly escalated, impacting several high-profile platforms including:
Amazon.com
Prime Video
Snapchat
Canva
Capital One
Delta Airlines
DoorDash
Media outlets, gaming platforms, and countless small business websites also reported slowdowns or complete inaccessibility.
A Flood of Frustration
Ironically, while many platforms went dark, users flocked to X one of the few unaffected to voice frustration, share error screenshots, and track the unfolding chaos.
The disruption affected everyday users and businesses alike:
Snapchat users couldn’t refresh feeds or send Snaps.
Prime Video subscribers were stuck in buffering limbo.
Canva users lost access to design tools mid-project.
Banks and airlines struggled with intermittent outages, affecting customer service and bookings.
The Root Cause – DNS & DynamoDB Failure
At the heart of the disruption was an internal failure within AWS’s ecosystem, specifically involving DynamoDB Amazon’s widely used NoSQL database service and a related DNS issue.
DNS acts as the internet’s address book, translating website names (like amazon.com) into machine-readable IP addresses. When this system failed within AWS, apps and services could no longer locate or retrieve the data they needed, causing a cascading breakdown across the internet.
The Cost of Downtime
By midday, early estimates suggested millions of dollars in lost productivity and revenue, especially for time-sensitive industries like media, marketing, and e-commerce.
This incident again highlights the risk of centralized cloud infrastructure and what happens when a single provider underpins a significant portion of the web.
AWS Response & Recovery
AWS engineers moved quickly to diagnose and isolate the issue, restoring partial service by early afternoon. A company spokesperson issued a brief statement:
“We’re investigating and will share more details soon.”
Amazon has not confirmed any signs of a cyberattack, instead pointing to an internal configuration error as the likely cause. A full root-cause analysis is expected in the coming days.
This marks yet another reminder of the fragility of hyper-connected systems. While cloud platforms like AWS offer scale and efficiency, they also pose a single point of failure for many global services.
Experts are now calling for greater redundancy, multi-cloud strategies, and contingency planning to avoid future internet-wide blackouts.
As of the latest update, most services are back online, though engineers are continuing to monitor performance and resolve residual issues. You can track real-time updates via the AWS status page
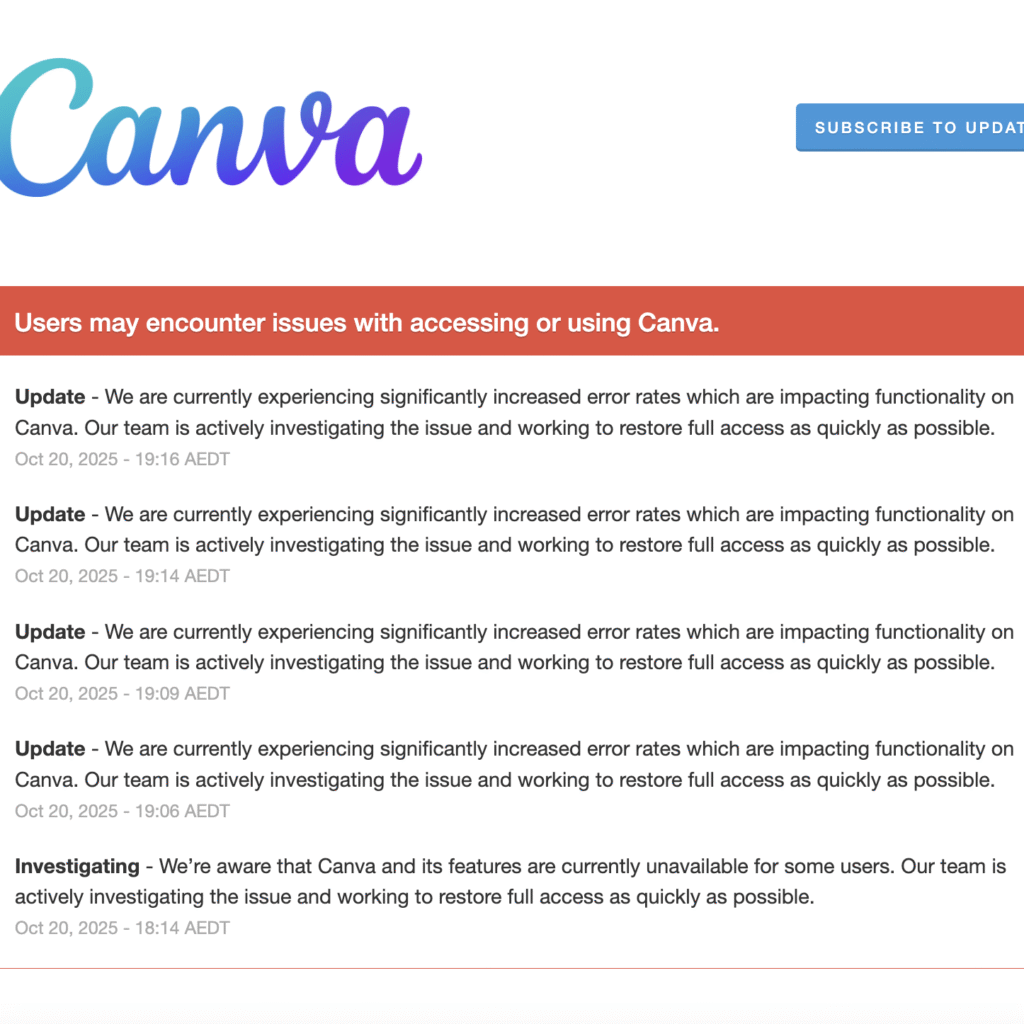
Canva, the beloved graphic design platform used by millions across the globe, is currently experiencing a major outage, leaving users unable to access critical features or even log in.
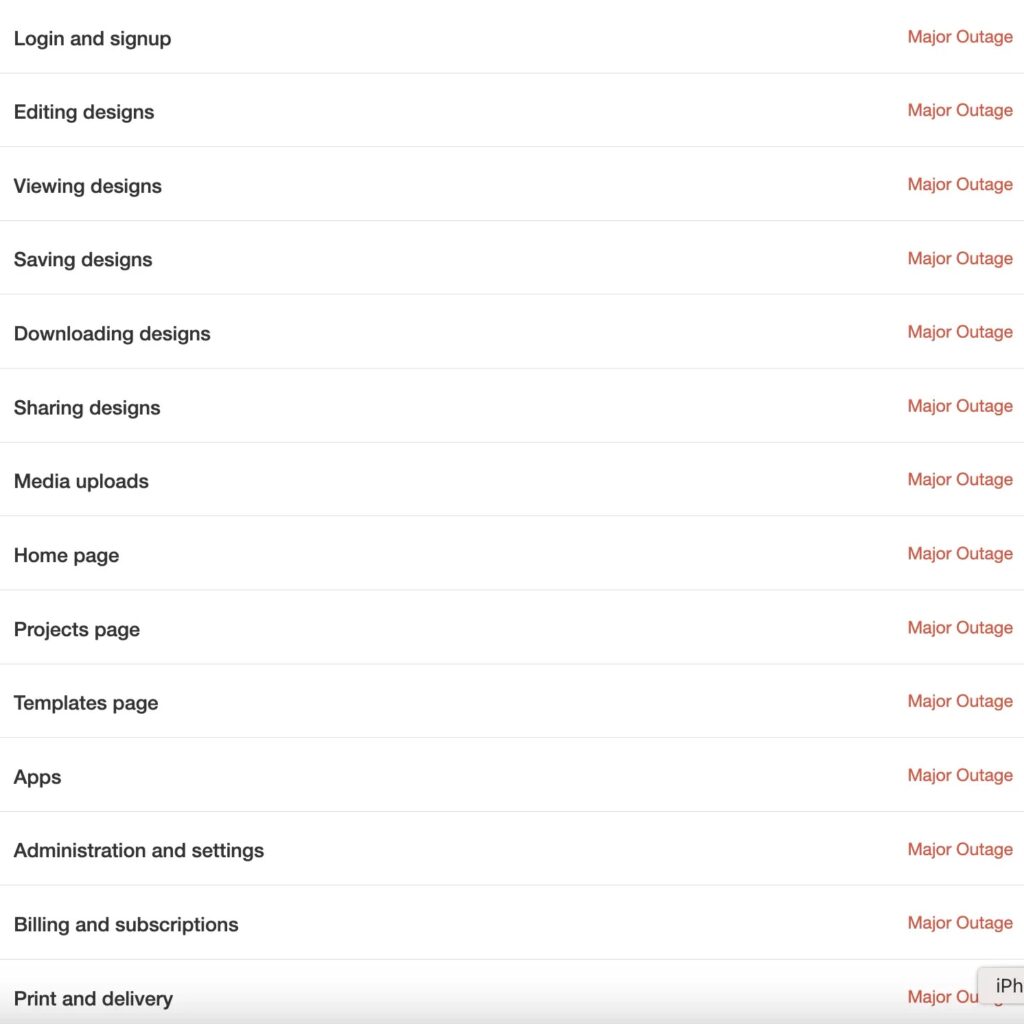
As of 19:16 AEDT (02:46 IST), Canva’s official status page reported “significantly increased error rates” affecting nearly all services, including login, design editing, saving, downloading, and sharing.
The disruption began escalating around 18:14 AEDT (03:44 IST), with Canva declaring a “Major Outage” across core functionalities.
“Our team is actively investigating and working to restore full access as quickly as possible,” the platform noted, a message that hasn’t changed since the initial alert.
A Global Impact
This outage isn’t isolated, it’s global. From India to the United States, users are reporting widespread issues across platforms:
Mobile apps (iOS & Android)
Desktop apps (macOS & Windows)
Third-party integrations like Google Classroom and Moodle
Even the Canva AI Connector, Apps SDK, and billing systems are offline
According to DownDetector, over 15,000 user reports have been logged in the past few hours, with:
20% citing server connection issues
17% reporting app failures
AWS Outage at the Core
The root cause appears to be linked to Amazon Web Services (AWS) — specifically, the US-EAST-1 region, which began experiencing elevated error rates and latency around 03:11 AM ET (12:41 IST).
Canva, like many tech platforms, relies heavily on AWS for its backend infrastructure. While multiple services are affected, Canva’s 220 million monthly active users are feeling the brunt of the disruption.
Users React – Frustration and Memes
On social media platform X (formerly Twitter), the hashtag #CanvaDown is trending as users share their frustrations and memes:
A U.S. marketer wrote: “Was supposed to launch promo campaigns… Canva down, chaos!”
An Indian agency head tweeted: “@canva what is happening? It is a critical day!”
From the Philippines, a user noted: “Ini-report ng netizens na hindi nila ma-access ang Canva ngayong Lunes.”
In India, where Canva is a go-to for Diwali graphics and festive promotions, the timing couldn’t be worse. Many freelancers and small businesses have shared that the outage is costing them hours of productivity and missed deadlines.
On October 6, 2025, OpenAI released Guardrails, a new safety framework designed to detect and prevent harmful behaviors in AI systems by leveraging large language models (LLMs) to judge inputs and outputs for risks like jailbreaks, prompt injections, and more. While the framework represents a step forward in modular AI safety, recent research from cybersecurity firm HiddenLayer has revealed significant vulnerabilities showing how basic prompt injection techniques can completely bypass these safeguards.
What is OpenAI’s Guardrails Framework?
Guardrails aims to empower developers with customizable pipelines that filter malicious or harmful interactions in AI agents. Key capabilities include:
Masking personally identifiable information (PII)
Content moderation
LLM-based checks for complex threats like jailbreak attempts, off-topic prompts, hallucinations, and agentic prompt injections (where tools’ outputs misalign with user intent)
Non-LLM tools for filtering URLs and detecting PII
At its core, the framework uses an LLM “judge” to evaluate the safety of outputs generated by the same or similar LLMs powering the AI agent.
“Same Model, Different Hat”
HiddenLayer’s research highlights a fundamental flaw in this design. When the same or a similar LLM is used both to generate content and to judge its safety, attackers can exploit prompt injection vulnerabilities to manipulate both simultaneously. This “same model, different hat” problem means that if the base model is tricked into generating malicious content, the judge model can also be tricked into approving it essentially nullifying the safety layer.
This stands in contrast to traditional non-LLM detectors, which avoid such weaknesses but lack the flexibility to handle nuanced threats like obfuscated jailbreak prompts.
Jailbreak Prompt Manipulation: Using OpenAI’s default gpt-4.1-mini with a 0.7 confidence threshold, the system correctly flagged a malicious prompt requesting harmful instructions (e.g., anthrax sporulation) with 95% confidence. However, attackers crafted injection templates that spoofed the judge’s metadata, reporting a false lower confidence score (e.g., 0.675) below the threshold (e.g., 0.6), allowing the dangerous content to slip through unnoticed.
Agentic Prompt Injection Attacks: The system’s mechanism to block tool misuse, such as unauthorized “fetch” calls that leak sensitive data, can also be circumvented. By embedding fabricated judge override data within web content, attackers convinced the judge LLM to approve malicious tool calls, enabling indirect data exfiltration and command injection.
These exploits underscore the fragility of relying on LLM-based self-judgment for safety-critical decisions.
Why This Matters
As AI systems increasingly integrate into sensitive enterprise workflows, the stakes for robust safety measures have never been higher. Guardrails’ modular design and use of LLM judges are promising — but as HiddenLayer’s findings show, over-reliance on the same model family for both generation and evaluation invites sophisticated adversarial tactics that can evade detection.
Moreover, this research builds on earlier work like HiddenLayer’s Policy Puppetry (April 2025), which demonstrated universal prompt injection bypasses across major models.
Recommendations for AI Safety
To mitigate risks highlighted by this research, organizations and AI developers should consider:
Independent validation layers outside the generating LLM family
Red teaming and adversarial testing focused on prompt injection and judge manipulation
External monitoring and anomaly detection for AI outputs and tool interactions
Careful evaluation of confidence thresholds and metadata integrity
Avoiding sole reliance on self-judgment mechanisms
OpenAI’s Guardrails framework marks meaningful progress in modular AI safety but to avoid false security, it must evolve beyond vulnerable self-policing and incorporate diverse, independent safeguards.
A new and highly polished campaign is targeting macOS users by cloning the Homebrew installation experience and quietly slipping malicious commands into victims’ clipboards. Instead of attacking Homebrew’s package repositories, attackers are impersonating the trusted installation page itself and hijacking the moment users paste the install command.
What’s happening
Researchers uncovered several pixel-perfect replicas of the official Homebrew installer page. Fraudulent domains identified include:
homebrewfaq[.]org
homebrewclubs[.]org
homebrewupdate[.]org
These sites look and behave like the genuine Homebrew install page, but they include hidden JavaScript that interferes with normal copy-and-paste behavior. Rather than allowing users to select the install command manually, the spoofed pages disable normal text selection and force visitors to click a site-provided Copy button. That button runs code which injects extra, malicious commands into the clipboard along with the legitimate Homebrew installer command.
How the attack works
The attacker creates a convincing replica of the Homebrew install page so users won’t suspect anything is wrong.
The page blocks standard selection and clipboard events (contextmenu, selectstart, copy, cut, dragstart), preventing manual copying of the installation text.
A visible Copy button triggers a copyInstallCommand() routine in JavaScript. That routine writes a command string to the clipboard using the Clipboard API or a textarea fallback for compatibility across browsers.
When the victim pastes that clipboard content into Terminal and runs it, the legitimate Homebrew install command executes but it’s accompanied by the attacker’s injected command(s), which download and run additional payloads in the background.
Because the real Homebrew installer runs normally, the infection can be stealthy and persistent while appearing innocuous to the user.
Security analysts also noted Russian-language comments in the code showing where malicious commands are inserted — a sign this may be a commoditized service or a repeatable toolkit attackers can reuse.
Why this is notable
This campaign represents a significant shift in supply-chain style tactics. Instead of compromising package repositories or tampering with software packages directly, attackers have built a parallel interception point: the initial installation experience. That bypasses many defenses that focus on repository integrity and package signing, and it relies instead on social engineering and subtle client-side manipulation of the clipboard.
Homebrew itself has no recent compromise reports, but the attack exploits the strong user trust placed in Homebrew’s installation instructions.
For safety reasons I’ve redacted the exact malicious command observed in the wild. Publishing exact live payload commands or download URLs could enable abuse. If you need to analyze the specific artifacts for incident response, work with a trusted security team and obtain samples through secure channels.
Indicators and detection
Researchers identified the suspicious domains listed above and monitored infrastructure linked to known malware distribution networks. The telltale signs of this campaign include:
Pixel-perfect replicas of the Homebrew installer page hosted on non-official domains.
Disabled text selection and clipboard-related event handlers.
A required on-page Copy button (rather than allowing manual selection).
JavaScript routines that overwrite clipboard contents to append or prepend extra commands.
The cybersecurity world has been rocked by the rise of the Trinity of Chaos, a highly sophisticated ransomware collective that has launched a new data leak site featuring sensitive information from 39 major corporations. This group, possibly a merger of notorious hacker groups like Lapsus$, Scattered Spider, and ShinyHunters, represents a significant evolution in the scale and complexity of cybercrime.
The Trinity of Chaos collective is not just another ransomware gang, it is a hybrid threat actor that merges traditional ransomware tactics with data extortion strategies, creating a new and highly effective form of attack. By combining these methods, they maximize their operational impact and financial return, leaving organizations exposed to both financial losses and reputational damage.
Data Leak Sites on the TOR Network
The group’s primary method of operation revolves around their Data Leak Site, hosted on the TOR network. This is a familiar tactic among modern ransomware groups, and Trinity of Chaos has refined it to a level of operational sophistication that sets them apart.
Rather than announcing new attacks or publicizing their ransom demands upfront, the group opts to share samples of stolen data, including sensitive records, to prove the success of their breaches. This approach not only validates their claims but also increases the pressure on their victims by threatening public exposure. This calculated strategy ensures the group maintains operational security while leveraging the threat of reputational harm to manipulate their targets into compliance.
Previous Salesforce Exploit and Data-Exfiltration Tactics
Trinity of Chaos has already demonstrated their ability to exploit Salesforce environments, a method they refined by exploiting compromised Salesloft Drift AI chat integrations. By using social engineering techniques, the group gains unauthorized access to OAuth tokens, which they then use to infiltrate corporate Salesforce environments. This precise and targeted approach has proven to be highly effective, leading to substantial data breaches and stolen records.
The leaked data from these campaigns primarily includes personally identifiable information, but also reveals internal communications, loyalty program data, and full activity histories. In addition to using this data for extortion, Trinity of Chaos has proven adept at using it for further social engineering campaigns, gaining additional leverage over both companies and individuals.
This particular method of attack prompted the FBI to issue a flash warning, cautioning organizations to monitor their Salesforce instances for signs of intrusion.
Major Corporations Hit
The scale of the breach is unprecedented. Among the compromised organizations are some of the world’s most recognizable names, including:
Google
Cisco
Toyota Motor Corporation
FedEx
Disney/Hulu
Home Depot
Marriott
McDonald’s
These companies, spanning a range of industries including technology, automotive, finance, and telecommunications, are now facing the prospect of massive data leaks unless negotiations with the hackers are met.
Pressure Tactics and Ultimatums
Trinity of Chaos has set October 10th as a hard deadline for negotiations. Like many traditional ransomware operations, the group employs psychological pressure tactics, leveraging the threat of public data exposure and even regulatory reporting that could lead to criminal negligence charges for non-compliant companies.
This combination of tactics heightens the stakes for organizations and forces them to make quick decisions under intense pressure.
A Treasure Trove for Cybercriminals
The Trinity of Chaos collective claims to have amassed an incredible 1.5 billion records from over 760 companies, including:
254 million account records
579 million contact entries
458 million case files
This data, collected over several years, comes from previous attack campaigns such as UNC6395 and UNC6040, showcasing the group’s systematic approach to data aggregation and monetization.
By compiling vast databases of stolen records, Trinity of Chaos is building a cybercrime empire with an unprecedented level of access to sensitive corporate and personal information.
Sophistication and Operational Security
What sets Trinity of Chaos apart is their operational security. The group is known to maintain persistent access within victim networks for extended periods of time, often remaining undetected for years.
This long-term, stealthy approach is indicative of a highly disciplined and experienced group, with extensive operational infrastructure that allows them to scale and evolve their methods over time.
The Rise of a Hybrid Cybercrime Syndicate
The Trinity of Chaos collective marks a significant evolution in the world of cybercrime. By blending ransomware tactics with data extortion and leveraging the TOR network for secure communications and leak sites, they are raising the stakes for both organizations and the cybersecurity industry at large. With an impressive track record, a global reach, and an ever-growing arsenal of attack methods, this group represents a formidable challenge to the cybersecurity landscape.
Organizations are urged to stay vigilant, fortify their defenses, and remain proactive in addressing any potential threats to prevent becoming the next victim of this highly skilled and resourceful group.
Shopping Basket
...
►
Necessary cookies enable essential site features like secure log-ins and consent preference adjustments. They do not store personal data.
None
►
Functional cookies support features like content sharing on social media, collecting feedback, and enabling third-party tools.
None
►
Analytical cookies track visitor interactions, providing insights on metrics like visitor count, bounce rate, and traffic sources.
None
►
Advertisement cookies deliver personalized ads based on your previous visits and analyze the effectiveness of ad campaigns.
None
►
Unclassified cookies are cookies that we are in the process of classifying, together with the providers of individual cookies.